on
Concourse CI: Pipeline Flow
This is just a small contribution for those starting with Concourse CI. As Concourse claims to be built on the simple mechanics of resources, tasks, and job, I will assume you are already familiar with these concepts.
The diagram below is just a visual representation of how data may flow from task to task and from job to job within a pipeline (only taking into account: get, put and task steps).
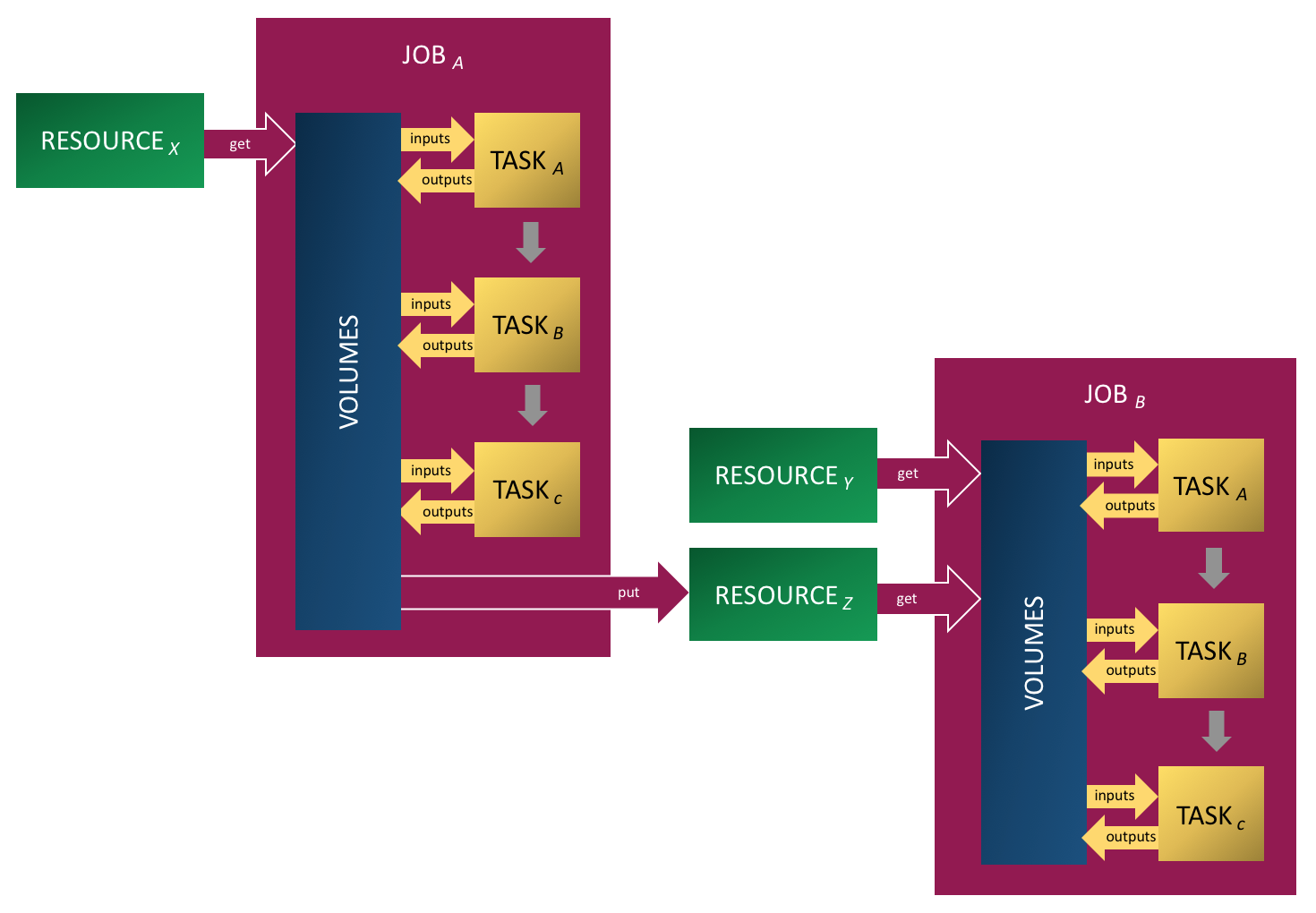 Concourse pipeline flow
Concourse pipeline flow
Each arrow contains a description (get, put, inputs, outputs) that maps directly to the key you will use in your pipeline YAML definition. The diagram above could be written as the following pseudo-pipeline:
---
resources:
- name: resource-x
type: git
source: # (...)
- name: resource-y
type: git
source: # (...)
- name: resource-z
type: artifactory
source: # (...)
jobs:
- name: job-a
plan:
- get: resource-x
- task: task-a
config:
platform: # (...)
image_resource: # (...)
inputs:
- name: resource-x
run: # (...)
outputs:
- name: my-result-a
- task: task-b
config:
platform: # (...)
image_resource: # (...)
inputs:
- name: my-result-a
run: # (...)
outputs:
- name: my-result-b
- task: task-c
config:
platform: # (...)
image_resource: # (...)
inputs:
- name: my-result-b
run: # (...)
outputs:
- name: resource-z
- put: resource-z
- name: job-b
plan:
- get: resource-y
- task: task-a
config:
platform: # (...)
image_resource: # (...)
inputs:
- name: resource-y
run: # (...)
outputs:
- name: my-result-a
- task: task-b
config:
platform: # (...)
image_resource: # (...)
inputs:
- name: my-result-a
run: # (...)
outputs:
- name: my-result-b
- task: task-c
config:
platform: # (...)
image_resource: # (...)
inputs:
- name: my-result-b
run: # (...)
outputs:
- name: # (...)
# and so on...
Even though the official documentation only covers volumes from a reasonably broad perspective, I think it’s essential to understand their role within a pipeline context a bit deeper.
Volumes
Work in progress…